current actions artifacts implementation only support single file
artifact. To support multiple files uploading, it needs:
- save each file to each db record with same run-id, same artifact-name
and proper artifact-path
- need change artifact uploading url without artifact-id, multiple files
creates multiple artifact-ids
- support `path` in download-artifact action. artifact should download
to `{path}/{artifact-path}`.
- in repo action view, it provides zip download link in artifacts list
in summary page, no matter this artifact contains single or multiple
files.
Close#25906

Succeeded logs:
```
[I] router: completed GET /root/test/issues/posters?&q=%20&_=1689853025011 for [::1]:59271, 200 OK in 127.7ms @ repo/issue.go:3505(repo.IssuePosters)
[I] router: completed GET /root/test/pulls/posters?&q=%20&_=1689853968204 for [::1]:59269, 200 OK in 94.3ms @ repo/issue.go:3509(repo.PullPosters)
```
Before: the concept "Content string" is used everywhere. It has some
problems:
1. Sometimes it means "base64 encoded content", sometimes it means "raw
binary content"
2. It doesn't work with large files, eg: uploading a 1G LFS file would
make Gitea process OOM
This PR does the refactoring: use "ContentReader" / "ContentBase64"
instead of "Content"
This PR is not breaking because the key in API JSON is still "content":
`` ContentBase64 string `json:"content"` ``
Issue filters are being used on repo list page and on milestone issues
page, and the code is mostly duplicated.
This PR does the following changes:
- move issue filters into a shared template
- allow filtering milestone issues by project, so no need to hide this
filter on milestone issues page
- remove some dead code (e. g. issue actions in milestone issues
template)
- fix label filter dropdown width
---------
Co-authored-by: 6543 <6543@obermui.de>
Before:
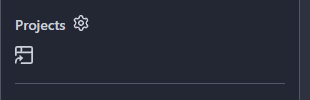
After:

This issue comes from the change in #25468.
`LoadProject` will always return at least one record, so we use
`ProjectID` to check whether an issue is linked to a project in the old
code.
As other `issue.LoadXXX` functions, we need to check the return value
from `xorm.Session.Get`.
In recent unit tests, we only test `issueList.LoadAttributes()` but
don't test `issue.LoadAttributes()`. So I added a new test for
`issue.LoadAttributes()` in this PR.
---------
Co-authored-by: Denys Konovalov <privat@denyskon.de>
This PR will display a pull request creation hint on the repository home
page when there are newly created branches with no pull request. Only
the recent 6 hours and 2 updated branches will be displayed.
Inspired by #14003
Replace #14003Resolves#311Resolves#13196Resolves#23743
co-authored by @kolaente
A couple of notes:
* Future changes should refactor arguments into a struct
* This filtering only is supported by meilisearch right now
* Issue index number is bumped which will cause a re-index
There are too many files under `routers/web/repo` and the file
`routers/web/repo/setting.go` is too big.
This PR move all setting related routers' body functions under
`routers/web/repo/setting` and also split `routers/web/repo/setting.go`
Related #14180
Related #25233
Related #22639Close#19786
Related #12763
This PR will change all the branches retrieve method from reading git
data to read database to reduce git read operations.
- [x] Sync git branches information into database when push git data
- [x] Create a new table `Branch`, merge some columns of `DeletedBranch`
into `Branch` table and drop the table `DeletedBranch`.
- [x] Read `Branch` table when visit `code` -> `branch` page
- [x] Read `Branch` table when list branch names in `code` page dropdown
- [x] Read `Branch` table when list git ref compare page
- [x] Provide a button in admin page to manually sync all branches.
- [x] Sync branches if repository is not empty but database branches are
empty when visiting pages with branches list
- [x] Use `commit_time desc` as the default FindBranch order by to keep
consistent as before and deleted branches will be always at the end.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Close#20976Close#20975
1. Fix the bug: the TOC in footer was incorrectly rendered as main
content's TOC
2. Fix the layout: on mobile, the TOC is put above the main content,
while the sidebar is put below the main content
3. Auto collapse the TOC on mobile
ps: many styles of "wiki.css" are moved from old css files, so leave
nits to following PRs.
Refactor `modules/indexer` to make it more maintainable. And it can be
easier to support more features. I'm trying to solve some of issue
searching, this is a precursor to making functional changes.
Current supported engines and the index versions:
| engines | issues | code |
| - | - | - |
| db | Just a wrapper for database queries, doesn't need version | - |
| bleve | The version of index is **2** | The version of index is **6**
|
| elasticsearch | The old index has no version, will be treated as
version **0** in this PR | The version of index is **1** |
| meilisearch | The old index has no version, will be treated as version
**0** in this PR | - |
## Changes
### Split
Splited it into mutiple packages
```text
indexer
├── internal
│ ├── bleve
│ ├── db
│ ├── elasticsearch
│ └── meilisearch
├── code
│ ├── bleve
│ ├── elasticsearch
│ └── internal
└── issues
├── bleve
├── db
├── elasticsearch
├── internal
└── meilisearch
```
- `indexer/interanal`: Internal shared package for indexer.
- `indexer/interanal/[engine]`: Internal shared package for each engine
(bleve/db/elasticsearch/meilisearch).
- `indexer/code`: Implementations for code indexer.
- `indexer/code/internal`: Internal shared package for code indexer.
- `indexer/code/[engine]`: Implementation via each engine for code
indexer.
- `indexer/issues`: Implementations for issues indexer.
### Deduplication
- Combine `Init/Ping/Close` for code indexer and issues indexer.
- ~Combine `issues.indexerHolder` and `code.wrappedIndexer` to
`internal.IndexHolder`.~ Remove it, use dummy indexer instead when the
indexer is not ready.
- Duplicate two copies of creating ES clients.
- Duplicate two copies of `indexerID()`.
### Enhancement
- [x] Support index version for elasticsearch issues indexer, the old
index without version will be treated as version 0.
- [x] Fix spell of `elastic_search/ElasticSearch`, it should be
`Elasticsearch`.
- [x] Improve versioning of ES index. We don't need `Aliases`:
- Gitea does't need aliases for "Zero Downtime" because it never delete
old indexes.
- The old code of issues indexer uses the orignal name to create issue
index, so it's tricky to convert it to an alias.
- [x] Support index version for meilisearch issues indexer, the old
index without version will be treated as version 0.
- [x] Do "ping" only when `Ping` has been called, don't ping
periodically and cache the status.
- [x] Support the context parameter whenever possible.
- [x] Fix outdated example config.
- [x] Give up the requeue logic of issues indexer: When indexing fails,
call Ping to check if it was caused by the engine being unavailable, and
only requeue the task if the engine is unavailable.
- It is fragile and tricky, could cause data losing (It did happen when
I was doing some tests for this PR). And it works for ES only.
- Just always requeue the failed task, if it caused by bad data, it's a
bug of Gitea which should be fixed.
---------
Co-authored-by: Giteabot <teabot@gitea.io>
this will allow us to fully localize it later
PS: we can not migrate back as the old value was a one-way conversion
prepare for #25213
---
*Sponsored by Kithara Software GmbH*
1. The "web" package shouldn't depends on "modules/context" package,
instead, let each "web context" register themselves to the "web"
package.
2. The old Init/Free doesn't make sense, so simplify it
* The ctx in "Init(ctx)" is never used, and shouldn't be used that way
* The "Free" is never called and shouldn't be called because the SSPI
instance is shared
---------
Co-authored-by: Giteabot <teabot@gitea.io>
Follow up #22405Fix#20703
This PR rewrites storage configuration read sequences with some breaks
and tests. It becomes more strict than before and also fixed some
inherit problems.
- Move storage's MinioConfig struct into setting, so after the
configuration loading, the values will be stored into the struct but not
still on some section.
- All storages configurations should be stored on one section,
configuration items cannot be overrided by multiple sections. The
prioioty of configuration is `[attachment]` > `[storage.attachments]` |
`[storage.customized]` > `[storage]` > `default`
- For extra override configuration items, currently are `SERVE_DIRECT`,
`MINIO_BASE_PATH`, `MINIO_BUCKET`, which could be configured in another
section. The prioioty of the override configuration is `[attachment]` >
`[storage.attachments]` > `default`.
- Add more tests for storages configurations.
- Update the storage documentations.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
close#24540
related:
- Protocol: https://gitea.com/gitea/actions-proto-def/pulls/9
- Runner side: https://gitea.com/gitea/act_runner/pulls/201
changes:
- Add column of `labels` to table `action_runner`, and combine the value
of `agent_labels` and `custom_labels` column to `labels` column.
- Store `labels` when registering `act_runner`.
- Update `labels` when `act_runner` starting and calling `Declare`.
- Users cannot modify the `custom labels` in edit page any more.
other changes:
- Store `version` when registering `act_runner`.
- If runner is latest version, parse version from `Declare`. But older
version runner still parse version from request header.
## Changes
- Adds the following high level access scopes, each with `read` and
`write` levels:
- `activitypub`
- `admin` (hidden if user is not a site admin)
- `misc`
- `notification`
- `organization`
- `package`
- `issue`
- `repository`
- `user`
- Adds new middleware function `tokenRequiresScopes()` in addition to
`reqToken()`
- `tokenRequiresScopes()` is used for each high-level api section
- _if_ a scoped token is present, checks that the required scope is
included based on the section and HTTP method
- `reqToken()` is used for individual routes
- checks that required authentication is present (but does not check
scope levels as this will already have been handled by
`tokenRequiresScopes()`
- Adds migration to convert old scoped access tokens to the new set of
scopes
- Updates the user interface for scope selection
### User interface example
<img width="903" alt="Screen Shot 2023-05-31 at 1 56 55 PM"
src="https://github.com/go-gitea/gitea/assets/23248839/654766ec-2143-4f59-9037-3b51600e32f3">
<img width="917" alt="Screen Shot 2023-05-31 at 1 56 43 PM"
src="https://github.com/go-gitea/gitea/assets/23248839/1ad64081-012c-4a73-b393-66b30352654c">
## tokenRequiresScopes Design Decision
- `tokenRequiresScopes()` was added to more reliably cover api routes.
For an incoming request, this function uses the given scope category
(say `AccessTokenScopeCategoryOrganization`) and the HTTP method (say
`DELETE`) and verifies that any scoped tokens in use include
`delete:organization`.
- `reqToken()` is used to enforce auth for individual routes that
require it. If a scoped token is not present for a request,
`tokenRequiresScopes()` will not return an error
## TODO
- [x] Alphabetize scope categories
- [x] Change 'public repos only' to a radio button (private vs public).
Also expand this to organizations
- [X] Disable token creation if no scopes selected. Alternatively, show
warning
- [x] `reqToken()` is missing from many `POST/DELETE` routes in the api.
`tokenRequiresScopes()` only checks that a given token has the correct
scope, `reqToken()` must be used to check that a token (or some other
auth) is present.
- _This should be addressed in this PR_
- [x] The migration should be reviewed very carefully in order to
minimize access changes to existing user tokens.
- _This should be addressed in this PR_
- [x] Link to api to swagger documentation, clarify what
read/write/delete levels correspond to
- [x] Review cases where more than one scope is needed as this directly
deviates from the api definition.
- _This should be addressed in this PR_
- For example:
```go
m.Group("/users/{username}/orgs", func() {
m.Get("", reqToken(), org.ListUserOrgs)
m.Get("/{org}/permissions", reqToken(), org.GetUserOrgsPermissions)
}, tokenRequiresScopes(auth_model.AccessTokenScopeCategoryUser,
auth_model.AccessTokenScopeCategoryOrganization),
context_service.UserAssignmentAPI())
```
## Future improvements
- [ ] Add required scopes to swagger documentation
- [ ] Redesign `reqToken()` to be opt-out rather than opt-in
- [ ] Subdivide scopes like `repository`
- [ ] Once a token is created, if it has no scopes, we should display
text instead of an empty bullet point
- [ ] If the 'public repos only' option is selected, should read
categories be selected by default
Closes#24501Closes#24799
Co-authored-by: Jonathan Tran <jon@allspice.io>
Co-authored-by: Kyle D <kdumontnu@gmail.com>
Co-authored-by: silverwind <me@silverwind.io>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}